Abstract
SpatialTrackerV2 is a novel framework for 3D point tracking that estimates world-space 3D trajectories for arbitrary 2D pixels in monocular videos. Unlike previous methods that rely on offline depth and pose estimators, our approach decomposes 3D motion into scene geometry, camera ego-motion, and fine-grained point-wise motion, all within a fully differentiable, end-to-end architecture. This unified design enables scalable training across diverse data sources, including synthetic sequences, posed RGB-D videos, and unlabeled in-the-wild footage. By jointly learning geometry and motion, SpatialTrackerV2 achieves significant improvements—outperforming all prior 3D tracking methods by a clear margin, while also delivering strong results in 2D tracking and dynamic 3D reconstruction.
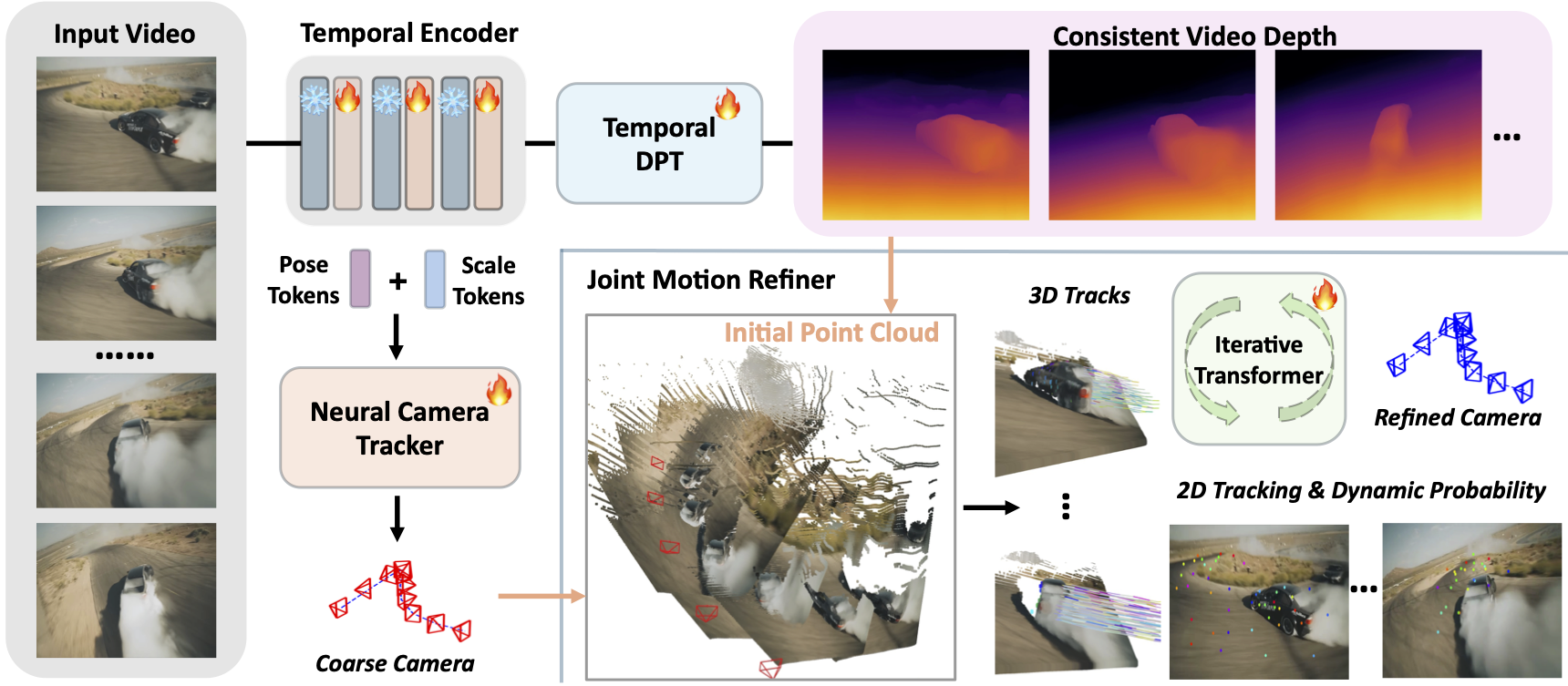
Method
Our method consists of two main components. First, a VGGT-style network extracts high-level semantic features from the input video to initialize consistent scene geometry and camera motion. Then, a track refiner iteratively updates all 4D attributes, including 2D and 3D point tracking, trajectory-wise dynamic probabilities, and camera poses.
Pipeline Overview
Interactive 4D Results
We present qualitative results of SpatialTrackerV2 across diverse scenarios. All results are generated by our model in a purely feed-forward manner, with inference taking only 10–20 seconds per sequence.

"Passing a basketball in Pstudio"

"A turtle swimming in the sea"

"The protagonist in Mission: Impossible rides a motorcycle."

"The dancer is performing a breakdance."
Acknowledgments
BibTeX
@inproceedings{xiao2025spatialtracker,
title={SpatialTrackerV2: 3D Point Tracking Made Easy},
author={Xiao, Yuxi and Wang, Jianyuan and Xue, Nan and Karaev, Nikita and Makarov, Iurii and Kang, Bingyi and Zhu, Xin and Bao, Hujun and Shen, Yujun and Zhou, Xiaowei},
booktitle={ICCV},
year={2025}
}